This document contains some notes that I took while studying educative.io course
Distributed Systems
Vertical scaling refers to the approach of scaling a system by adding resources (memory, CPU, disk, etc.) to a single node. Meanwhile, horizontal scaling refers to the approach of scaling by adding more nodes to the system.
Scalability
Scalability lets us store and process datasets much larger than what we could with a single machine.
Partitioning
Partitioning is the process of splitting a dataset into multiple, smaller datasets, and then assigning the responsibility of storing and processing them to different nodes of a distributed system. This allows us to add more nodes to our system and increase the size of the data it can handle.
- Vertical Partitioning
- Horizontal partitioning (Sharding)
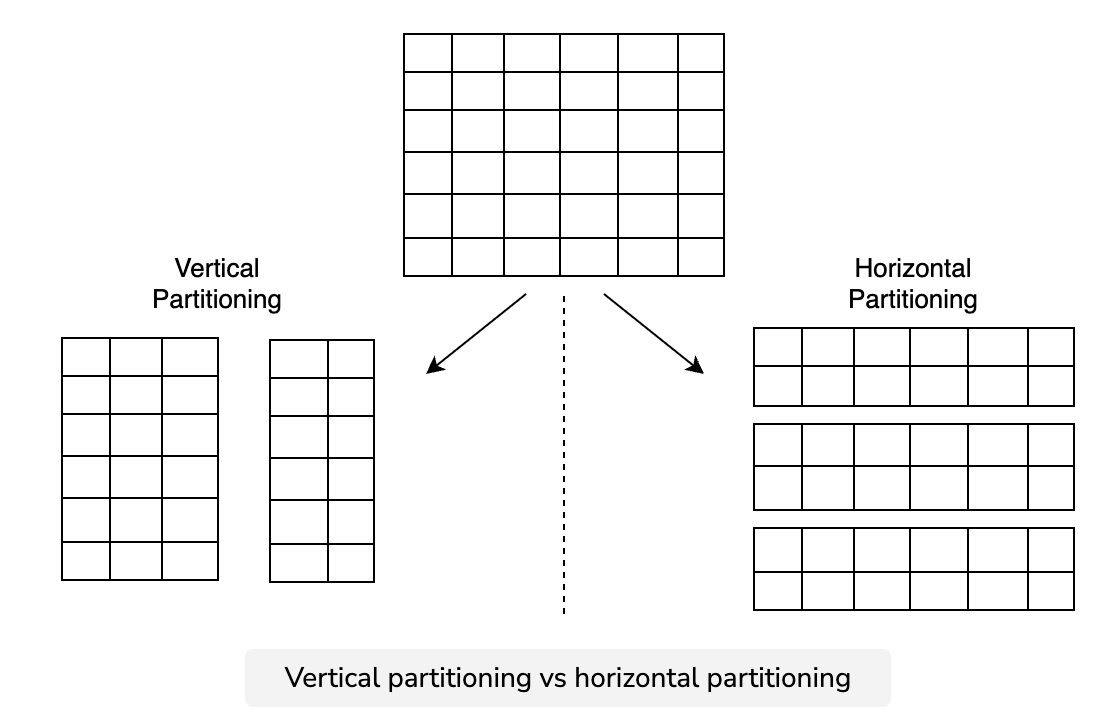
In a vertically partitioned system, requests that need to combine data from different tables (i.e., join operations) become less efficient. This is because these requests may now have to access data from multiple nodes.
In a horizontally partitioned system, we can usually avoid accessing data from multiple nodes because all the data for each row is located in the same node. However, we may still need to access data from multiple nodes for requests that are searching for a range of rows that belong to multiple nodes. Another important implication of horizontal partitioning is the potential for loss of transactional semantics.
There are a lot of different algorithms we can use to perform horizontal partitioning.
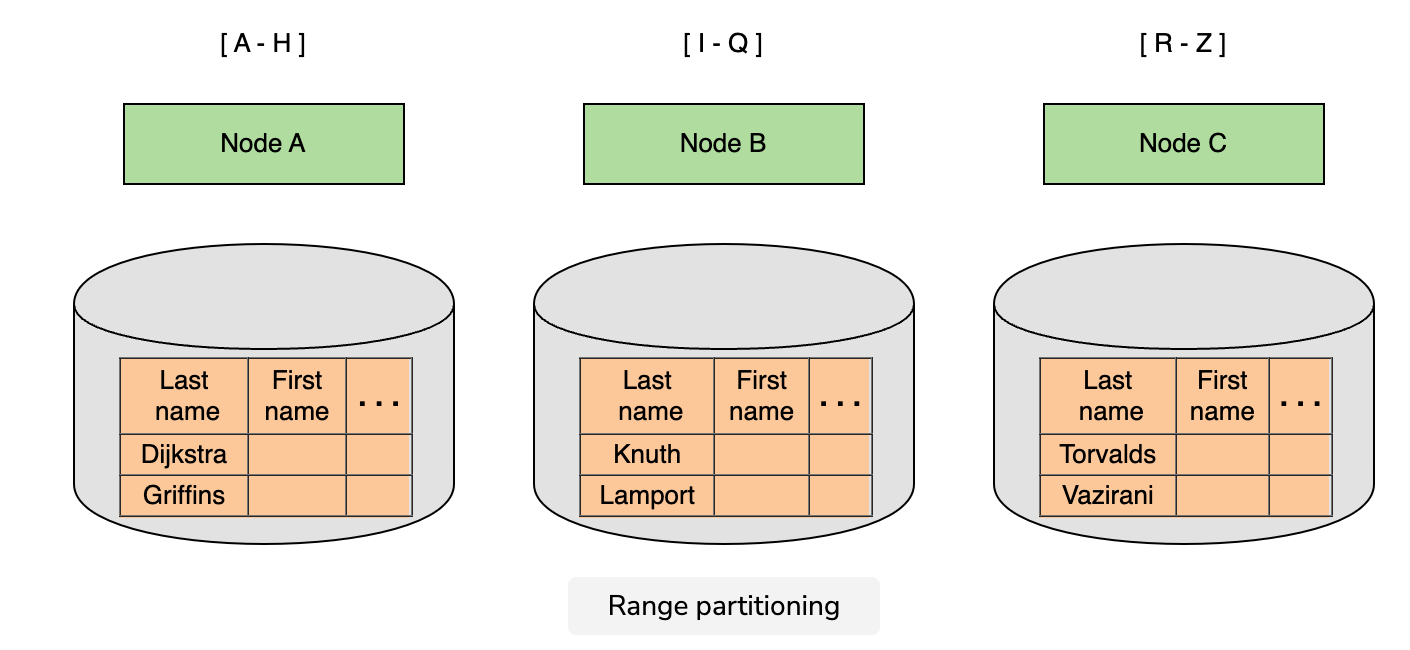
Range partitioning
Range partitioning is a technique where we split a dataset into ranges according to the value of a specific attribute. We then store each range in a separate node.
Hash partitioning
Hash partitioning is a technique where we apply a hash function to a specific attribute of each row. This results in a number that determines which partition—and, thus, node—this row belongs to.
Consistent hashing
Consistent hashing is a partitioning technique that is very similar to hash partitioning, but solves the increased data movement problem caused by hash partitioning.
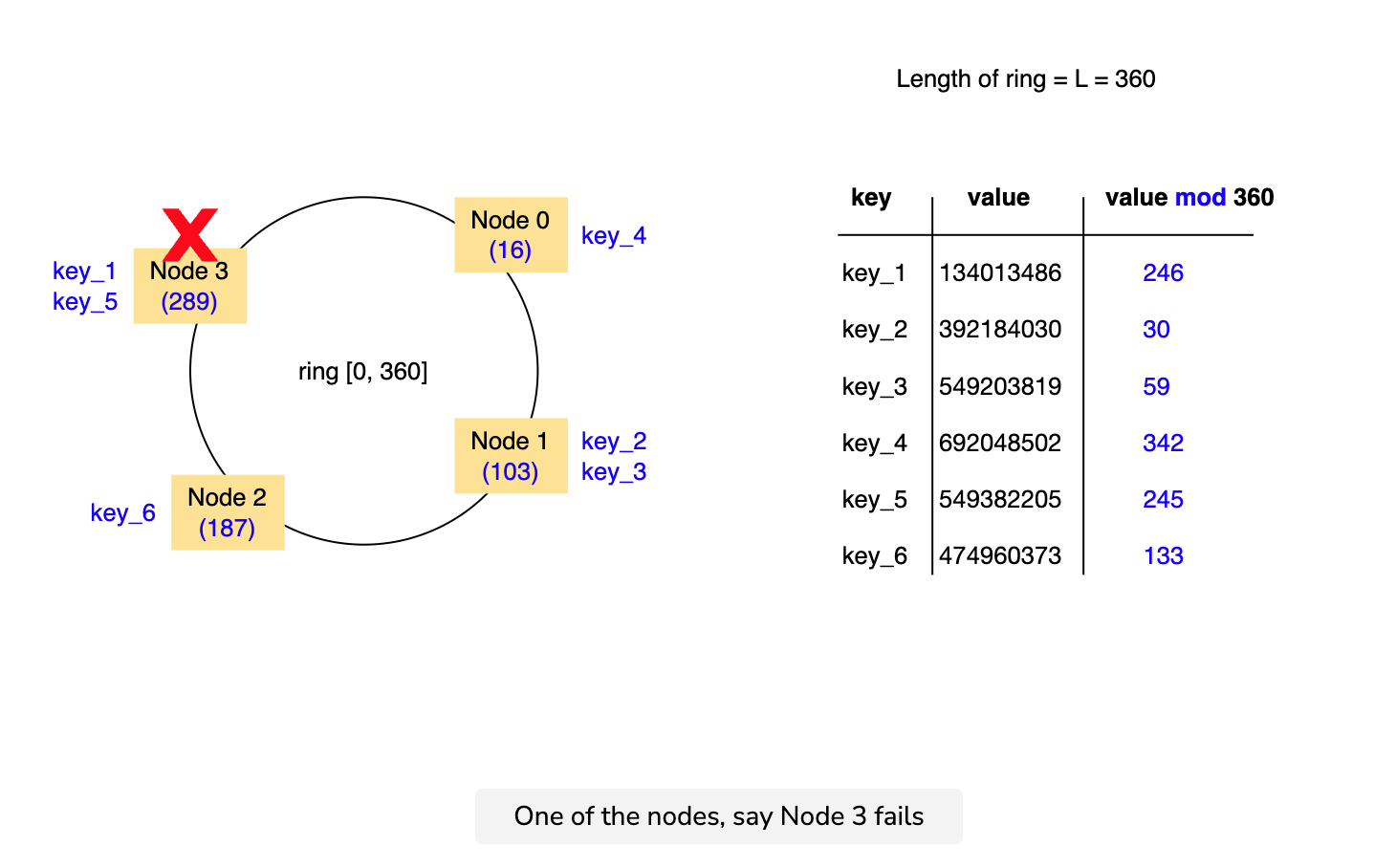
For further discussion on this concept, feel free to read the Dynamo paper. Another widely-used system that uses consistent hashing is Apache Cassandra.
Availability
Availability refers to the ability of the system to remain functional despite failures in parts of it.
Replication
Replication is the main technique used in distributed systems to increase availability. It consists of storing the same piece of data in multiple nodes (called replicas) so that if one of them crashes, data is not lost, and requests can be served from the other nodes in the meanwhile.
Pessimistic replication
Pessimistic replication tries to guarantee from the beginning that all the replicas are identical to each other—as if there was only one copy of the data all along.
Optimistic replication
Optimistic replication, or lazy replication, allows the different replicas to diverge. This guarantees that they will converge again if the system does not receive any updates, or enters a quiesced state, for a period of time.
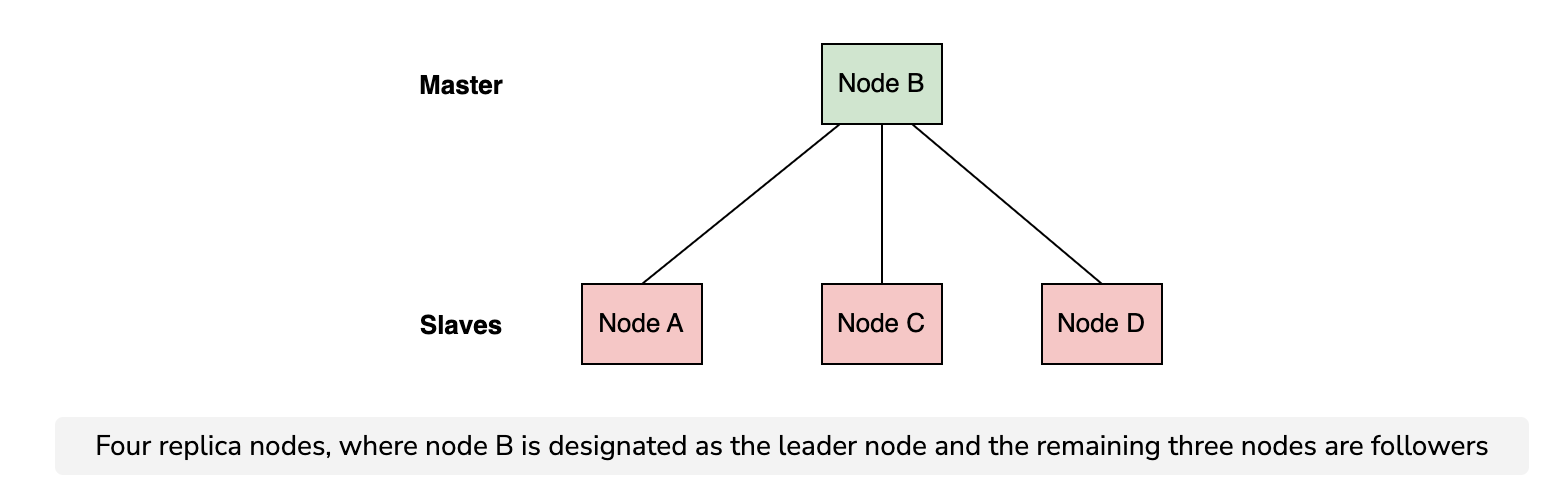
Single-master replication
Single-master replication is a technique where we designate a single node amongst the replicas as the leader, or primary, that receives all the updates.
This technique is also known as primary-backup replication.
Techniques for propagating updates
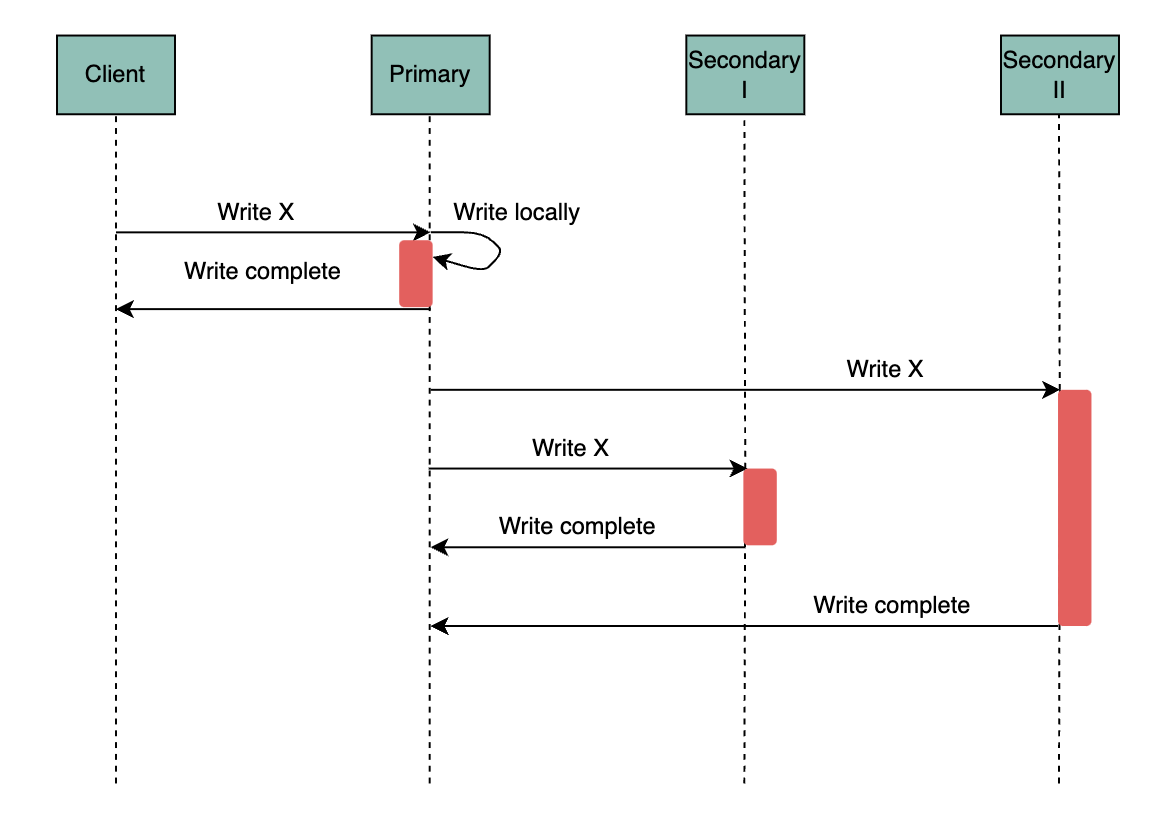
Synchronous replication
In synchronous replication, the node replies to the client to indicate the update is complete—only after receiving acknowledgments from the other replicas that they’ve also performed the update on their local storage. This guarantees that the client is able to view the update in a subsequent read after acknowledging it, no matter which replica the client reads from.
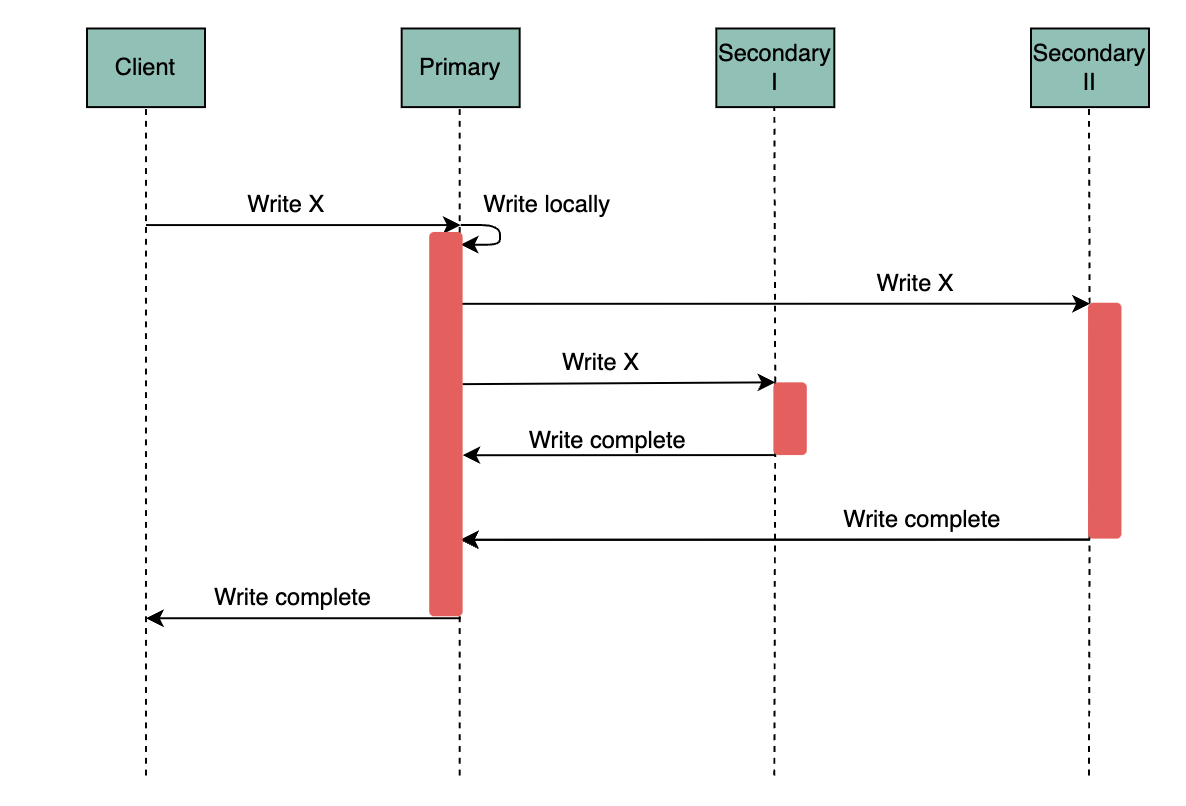
Asynchronous replication
In asynchronous replication, the node replies to the client as soon as it performs the update in its local storage, without waiting for responses from the other replicas.
Multi-Master Replication
In this technique, all replicas are equal and can accept write requests. They are also responsible for propagating the data modifications to the rest of the group.
Conflict resolution
There are many different ways to resolve conflicts, depending on the guarantees the system wants to provide.
An important aspect of different approaches to resolving conflicts is whether they do it eagerly or lazily.
- In the eagerly case, the conflict is resolved during the write operation.
- In the lazily case, the write operation proceeds to maintain multiple, alternative versions of the data record that are eventually resolved to a single version later on, i.e., during a subsequent read operation.
Quorums in Distributed Systems
Let’s consider an example. In a system of three replicas, we can say that writes need to complete in two nodes (as a quorum of two), while reads need to retrieve data from two nodes. This way, we can be sure that the reads will read the latest value. This is because at least one of the nodes in the read quorum will also be included in the latest write quorum.
Safety guarantors (ACID)
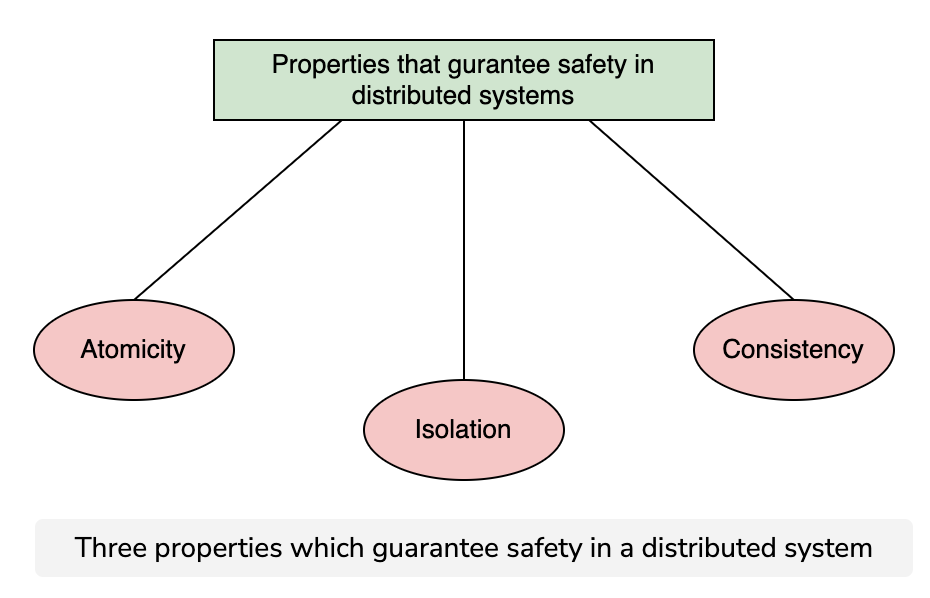
Atomicity
It is challenging to achieve atomicity in a distributed system because of the possibility of partial failures. Atomicity guarantees that a transaction that comprises multiple operations is treated as a single unit. This means that either all operations of the transaction are executed, or none of them is.
Consistency
It is challenging to achieve consistency because of the network asynchrony. Network asynchrony occurs when different nodes in a network have different values for the current time. The following illustration shows this. Consistency guarantees that a transaction only transitions the database from one valid state to another valid state, while maintaining any database invariants.
Isolation
It is challenging to achieve isolation because of the inherent concurrency of distributed systems. Isolation guarantees that even though transactions might run concurrently and have data dependencies, the result is as if one of them was executed at a time and there was no interference between them.
Durability
Durability guarantees that once a transaction is committed, it remains committed even in the case of failure. In the context of single-node, centralized systems, this usually means that completed transactions and their effects are recorded in non-volatile storage.
CAP Theorem
According to the initial statement of the CAP theorem, it is impossible for a distributed data store to provide more than two of the following properties simultaneously: consistency, availability, and partition tolerance.
a distributed system can be either consistent or available in the presence of a network partition.
“In the case of a network partition (P), the system has to choose between availability (A) and consistency (C) but else (E), when the system operates normally in the absence of network partitions, the system has to choose between latency (L) and consistency (C).”
Proof
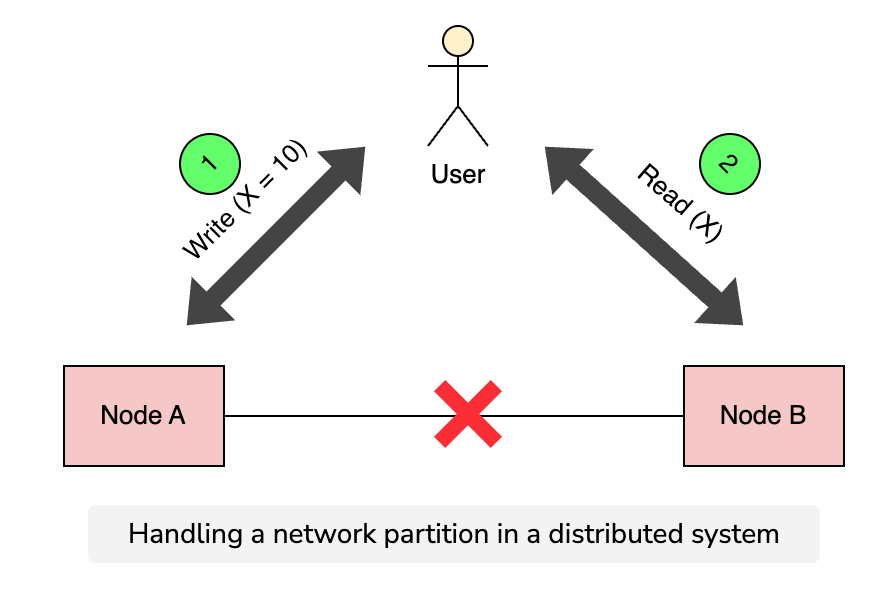
Now, let’s assume that there is a network failure that results in a network partition between the two nodes of the system at some point. A user of the system performs a write, and then a read—even two different users may perform these operations.
In that case, the system has two options:
- It can fail one of the operations, and break the availability property.
- It can process both the operations, which will return a stale value from the read and break the consistency property.
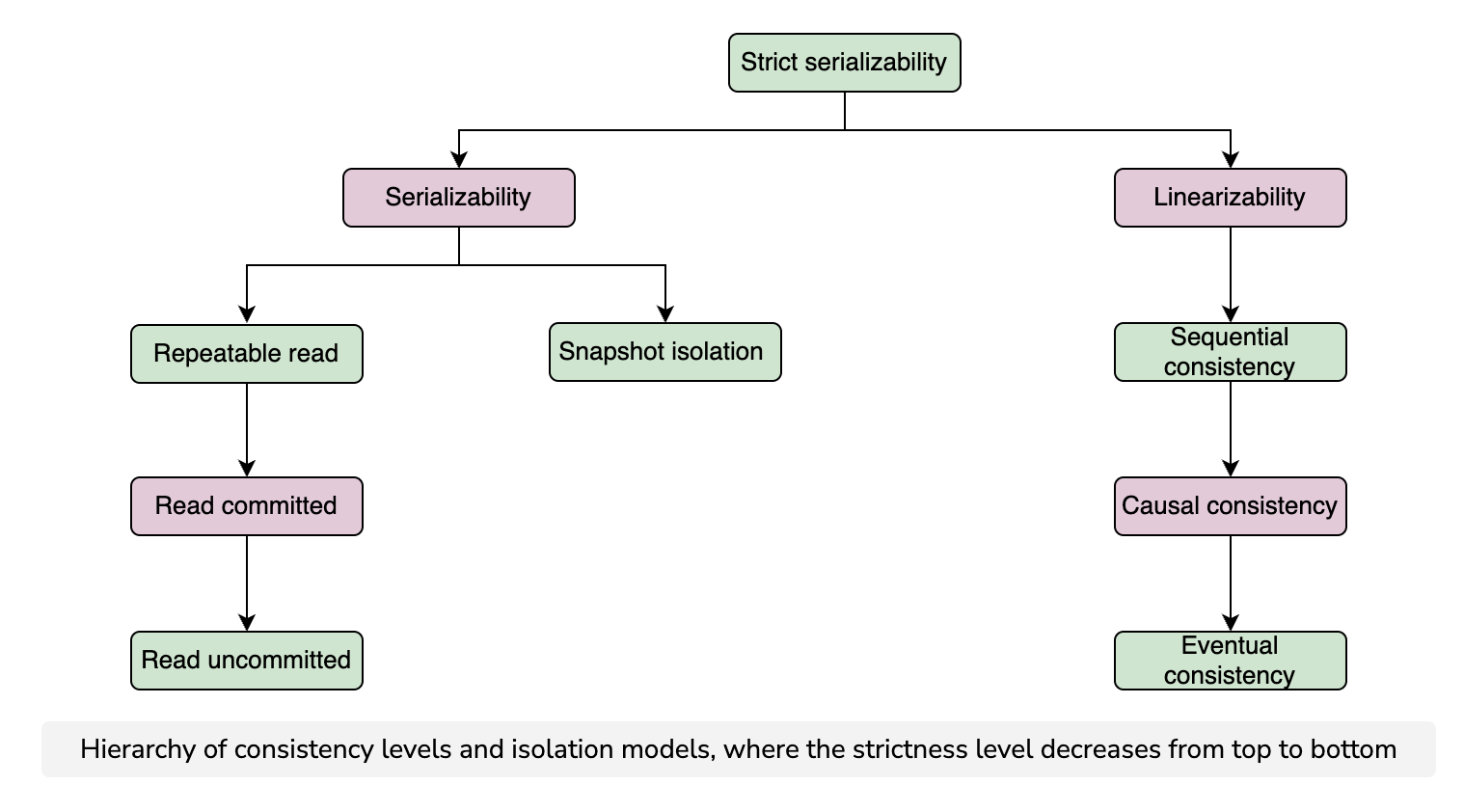
Consistency Model
The consistency model defines the set of execution histories that are valid in a system.
Strong consistency model
The consistency model defines the set of execution histories that are valid in a system.
Usually, the stronger the consistency model a system satisfies, the easier it is to build an application on top of it. This is because the developer can rely on stricter guarantees.
List of consistency models
- Linearizability
- operations appear to be instantaneous to the external client.
- The non-linearizability comes from the use of asynchronous replication.
- When we use a synchronous replication technique, we make the system linearizable.
- Sequential Consistency
- Sequential consistency is a weaker consistency model, where operations are allowed to take effect before their invocation or after their completion. As a result, it provides no real-time guarantees. However, operations from different clients have to be seen in the same order by all other clients, and operations of every single client preserve the order specified by its program (in this global order).
- Causal Consistency
- In some cases, we don’t need to preserve the ordering specified by each client’s program—as long as causally related operations are displayed in the right order. This is the causal consistency model, which requires that only operations that are causally related need to be seen in the same order by all the nodes.
- Eventual Consistency
- There are still even simpler applications that do not have the notion of a cause-and-effect and require an even simpler consistency model. The eventual consistency model is beneficial here.
Isolation Levels and Anomalies
There is still a need for some formal models that define what is possible and what is not in a system’s behavior. These are called isolation levels
- Serializability: It essentially states that two transactions, when executed concurrently, should give the same result as though executed sequentially.
- Repeatable read: It ensures that the data once read by a transaction will not change throughout its course.
- Snapshot isolation: It guarantees that all reads made in a transaction see a consistent snapshot of the database from the point it started and till the transaction commits successfully if no other transaction has updated the same data since that snapshot.
- Read committed: It does not allow transactions to read data that has not yet been committed by another transaction.
- Read uncommitted: It is the lowest isolation level and allows the transaction to read uncommitted data by other transactions.
Anomaly: Dirty write
A dirty write occurs when a transaction overwrites a value that was previously written by another transaction that is still in-flight and has not been committed yet.
Anomaly: Dirty read
A dirty read occurs when a transaction reads a value that has been written by another transaction that has not yet been committed.
Anomaly: Fuzzy or non-repeatable read
A fuzzy or non-repeatable read occurs when a value is retrieved twice during a transaction (without it being updated in the same transaction), and the value is different.
Anomaly: Phantom read
A phantom read occurs when a transaction does a predicate-based read, and another transaction writes or removes a data item matched by that predicate while the first transaction is still in flight. If that happens, then the first transaction might be acting again on stale data or inconsistent data.
Anomaly: Lost update
A lost update occurs when two transactions read the same value and then try to update it to two different values. The end result is that one of the two updates survives, but the process executing the other update is not informed that its update did not take effect. Thus it is called a lost update.
Anomaly: Read skew
A read skew occurs when there are integrity constraints between two data items that seem to be violated because a transaction can only see partial results of another transaction.
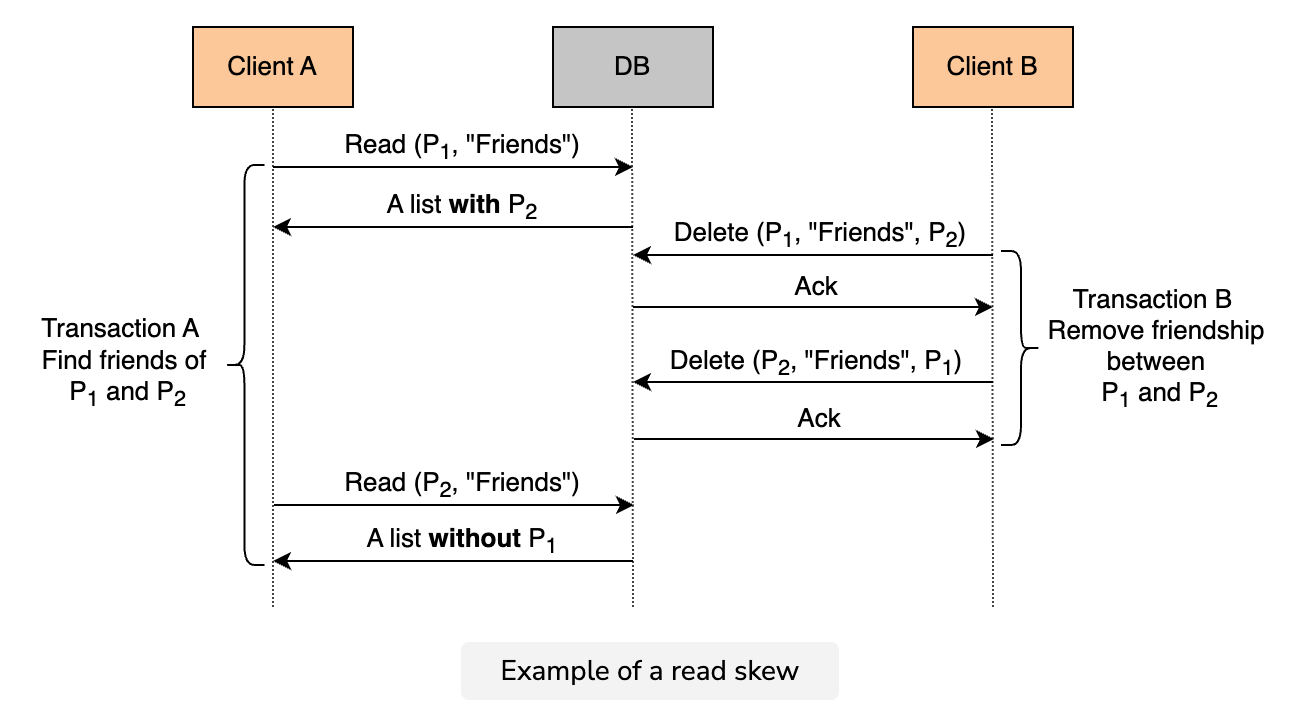
Anomaly: Write skew
A write skew occurs when two transactions read the same data, but then modify disjoint sets of data.
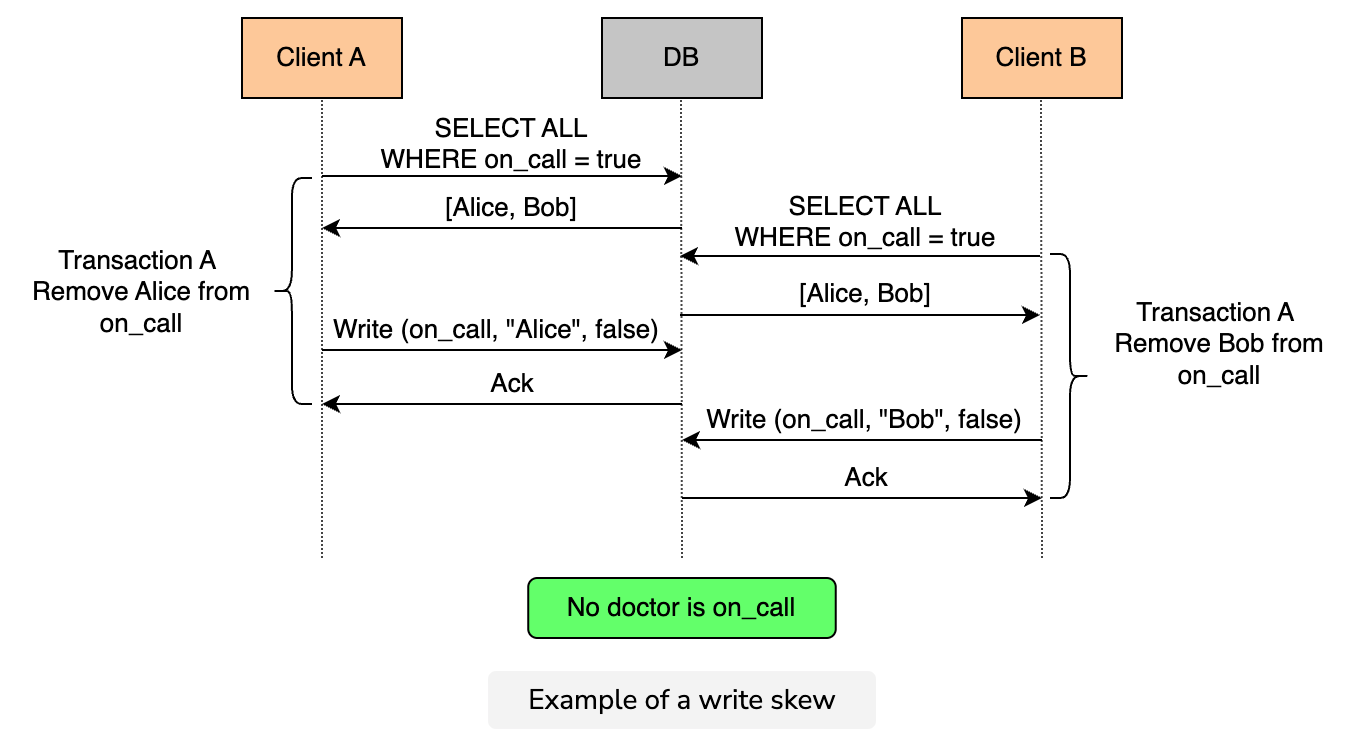

Models
Comments powered by Disqus.